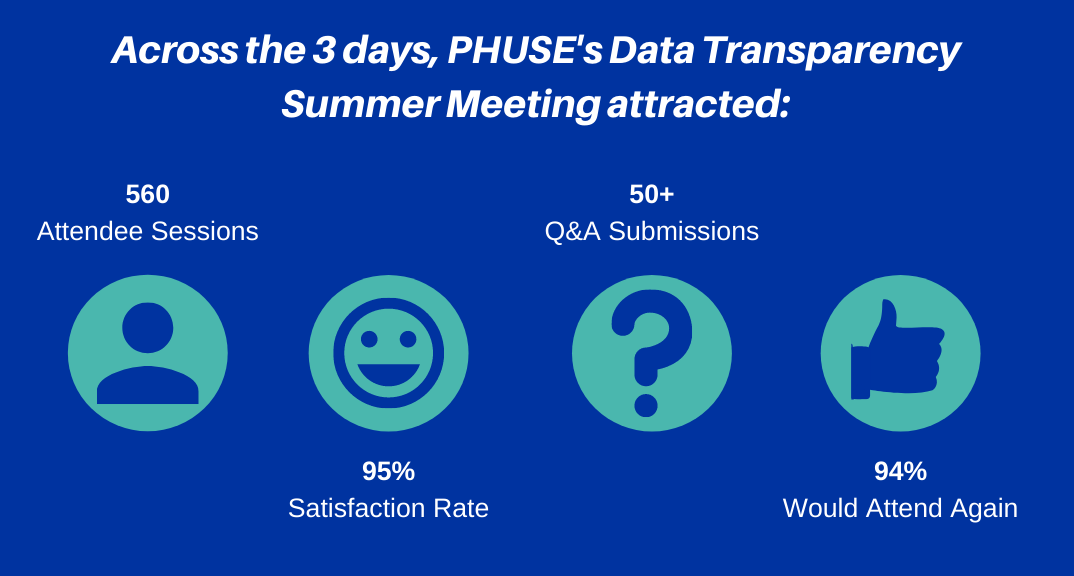
PHUSE has established itself as the world’s largest home for data transparency events. If you are passionate about advancing this fast-moving field, then this is the event for you! The third Data Transparency Event ran from 22nd–24th June and welcomed 560+ attendees across the three days. Each day hosted live presentations and a joint panel discussion/Q&A session based on the content from the day. A wide range of hot topics were discussed by our expert presenters in the data sharing field:
A fantastic 94% of attendees would attend again, so PHUSE are pleased to confirm our next Data Transparency Event is planned for March February 2022. | |
| |

Thank you to our DT Summer Event 2021 sponsors...A big thank you to all of our sponsors of the DT Summer Meeting 2021. This virtual event allowed us to screen our sponsors’ promotional videos in between presentation intervals, which was well received by our attendees.
|
|

A big thank you to our presenters across all three days, each day hosted live presentations and a joint panel discussion/Q&A session based on the content from the day.Take a look below at some of the Q&A highlights from the event. |
|
| Question | Answer |
|---|---|
Could you please provide examples around the concept of “all the means reasonably likely to be used”? What should we consider or not consider when, for example, sharing data with researchers under a portal or when data is put in the public domain (e.g. Pol70 or PRCI)? | The risks of re-identification will be higher in the public domain compared to release in a secure portal. The level of de-identification would need to be stronger if released to the public, for example further aggregation and using techniques like differential privacy. For open data release, the reasonably likely test would need to consider more types of motivated intruder who may wish to re-identify and also what data may be available in the public domain, e.g. social media. |
You mentioned “synthetic data” in your slides. Are there specific use cases where you believe synthetic data should be preferred? | Use cases could include health or financial data and also AI/ML projects needing access to training data – any use cases where sensitive data is processed such that synthetic data is necessary. The choice of technique is also an important consideration. |
Once the data is de-identified, how should one demonstrate the data utility while it is posted publicly? | The data utility needs to be sufficient for the purposes of the processing but should be respectful to the principle of data minimisation. How utility is demonstrated will depend on the de-identification technique used. For example, differential privacy and the amount of noise added can be measured accurately. |
From your experience, how much does the UK interpretation and methodology align with the GDPR? | I think they are aligned. We take a risk-based approach to anonymisation. Recital 26 of the GDPR also follows this approach by considering some of the objective factors that should be considered when assessing the risk of re-identification. |
| How often will updates occur? Will PHUSE and Xogene continue the collaboration for the updates? | Country-level information is checked weekly for updates. Industry news uses live feeds. PHUSE and Xogene will continue to collaborate on this initiative. |
| Will information about transparency initiatives in each country/region (such as EMA Policy 0070 and Health Canada PRCI) be included? | The plan is to include other transparency initiatives for the different regions in the portal (including EMA Policy 0070, Health Canada PRCI, ICMJE). |

